
200. 岛屿数量
Note: 深搜广搜均可。甚至本题不需要visited数组,因为可直接将访问过的陆地染成另一种颜色,主函数循环每一格子,若遇到未遍历过的陆地,则岛屿数+1,因为这说明这个格子在前面搜索整个岛屿时未被访问,是个“新大陆”。
695. 岛屿的最大面积
Note: 和上题一样,额外记录岛屿面积,在每一次岛屿搜索完成后更新最大面积即可。
1020. 飞地的数量
Note: 两种方法,第一种是计算所有不接触网格边界的岛屿面积总和(需要额外的标志来记录岛屿是否接触边界,初始为false,一旦在搜索过程中接触边界就置为true,每次搜索新岛屿前重置);第二种是从四个边界上的点开始对岛屿染色(淹没),剩下的岛屿就是飞地,直接记录所有飞地数量即可。
130. 被围绕的区域
Note: 同上题,不过上题是统计飞地数量,这题是将飞地全部染色。注意需要先将边缘岛屿染成第三种颜色,以区分于海洋,在染色飞地的同时把边缘岛屿染回原色。
417. 太平洋大西洋水流问题
Note: 如果对每个格子dfs看是否能到达两个大洋,那么复杂度将是O(n2m2),非常大,而且重复计算很多,因此考虑逆向推导,一个格子能流向边缘大洋,说明从边缘格子能够倒流向该格子,因此从四个边缘开始倒推,用两个二维bool数组(对应两个大洋)分别记录每个格子是否能由两个大洋倒流经过,然后做与运算。
827. 最大人工岛
Note: 本题主要思路分为两步:第一步,搜索每个岛屿,并将每个块染成一种颜色,颜色编号随岛屿数递增,并且记录这个岛屿面积,将(岛屿编号,岛屿面积)映射记录到一个字典里;第二步,搜索所有为0的位置,检查其上下左右格子里的数(此时只有0和其他岛屿编号,没有1),如果是岛屿编号就从字典里找到对应岛屿面积,累加,注意不能重复累加同一个岛屿的面积(因此这里需要用set做去重),用累加的面积+1去更新合并后的最大岛屿面积。
为了节省空间时间,这里用数组取代了map和set,而数组大小,也就是岛屿数量,首先要通过一遍遍历获得,也就是,第一遍遍历先染色并计算岛屿数量,然后初始化对应大小的数组,第二遍遍历去获取各个岛屿面积(此时各岛屿已经染色,因此对每一个岛屿格子,其对应岛屿面积(存于数组中)+1,这里可以记录岛屿面积最大值,如果最后等于row*col,那么整片区域全是陆地,直接提前返回该面积即可,不需要进行后续操作,否则浪费时间(这一情况下不会有0了,也就是说后面对0的检查是白费))。第三遍遍历则检查每个0的上下左右,并合并相连的岛屿面积,注意去重。
class Solution {
public:
int mark, row, col;
int dir[4][2] = {0, 1, 0, -1, 1, 0, -1, 0};
void dfs(vector<vector<int>>& grid, int x, int y) {
grid[x][y] = mark;
for (int i = 0; i < 4; ++i) {
int nextx = x + dir[i][0], nexty = y + dir[i][1];
if (nextx < 0 || nextx >= row || nexty < 0 || nexty >= col) continue;
if (grid[nextx][nexty] != 1) continue;
dfs(grid, nextx, nexty);
}
}
int largestIsland(vector<vector<int>>& grid) {
row = grid.size(); col = grid[0].size(); mark = 1;
bool isAllLand = true;
// 1. 统计岛屿数量,初始化(编号-面积)字典
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
if (grid[i][j] == 1) {
++mark;
dfs(grid, i, j);
}
}
}
int* areas = new int[mark + 1], ans = 0, area;
memset(areas, 0, sizeof(int) * (mark + 1));
// 2. 获取各个岛屿面积
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
if (grid[i][j] > 1) {
// 避免全为陆地情况的特殊处理,如果全为陆地,那么ans就是row*col,不会再变化
ans = max(ans, ++areas[grid[i][j]]);
}
}
}
if (ans == row * col) return ans;
// 3. 检查每个0,合并相连岛屿面积,获取最大值,注意用visited去重
bool* visited = new bool[mark + 1];
memset(visited, false, sizeof(bool) * (mark + 1));
int left, right, up, down;
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
if (grid[i][j] == 0) {
area = 1;
up = i > 0 ? grid[i - 1][j] : 0;
down = i < row - 1 ? grid[i + 1][j] : 0;
left = j > 0 ? grid[i][j - 1] : 0;
right = j < col - 1 ? grid[i][j + 1] : 0;
visited[up] = true;
area += areas[up];
if (!visited[right]) {
visited[right] = true;
area += areas[right];
}
if (!visited[down]) {
visited[down] = true;
area += areas[down];
}
if (!visited[left]) {
visited[left] = true;
area += areas[left];
}
visited[up] = visited[right] = visited[down] = visited[left] = false;
ans = max(ans, area);
}
}
}
return ans;
}
};
127. 单词接龙
Note: 本题两种方法:单向BFS或双向BFS。为什么一定要使用BFS呢?因为本题要求的是从beginWord到endWord,且中间单词全部在单词表里的最短距离,使用BFS的话,一层代表一步,最先找到endWord的那一层,当然就是最短的步数(距离),而DFS需要在每条路径里找最短的,反而更加麻烦,因此选用BFS。
对于获取下一层单词,我们不能直接去对每个当前单词在单词表里找与它距离为1的单词,这样太傻而且效率极低,而是需要对当前单词的一个位置突变,取各种可能字母(这里只有小写字母,所以只有26种情况),然后判断突变后单词是否在单词表中,如果是,才以突变单词作为下一层。由于突变单词可能出现重复情况(如ab -> ac -> dc和ab -> db -> dc),因此需要set类的数据结构来进行去重,记录一路上访问过的所有单词,由于我们追求路径最短,因此一旦发现当前突变单词存在于记录中,那么就抛弃,否则可能会产生无限循环。对于set去重,更好的办法是,将要记录的单词直接从单词表中删去,这样下次访问到一样的单词时,单词表里是找不到的,因此不会被加入下一层,也就等效于去重了,这样做既省去了set的额外开销,又减小了单词表的大小,一举两得。
在BFS搜索时,有两种办法,一种是单向BFS,用一个队列进行BFS,直到找到endWord为止,但这样有一个问题,在路径特别长时,搜索过程中会产生大量无用单词,造成很多不必要的开销,为了控制搜索树的大小,可采用双向BFS。
与单向BFS不同,双向BFS从两个方向(头和尾,这里是beginWord和endWord)同时搜索,直到两颗搜索树相遇。实际上这里的同时搜索并不是真的同时,而是交替搜索,也就是说有两颗搜索树,他们交替生长,直到彼此相遇为止,这里的相遇,指的是其中一颗树的最底层包含了另一颗树的最底层的节点,这样,两颗树最底层就可以合并形成一条闭合路径,而且这条路径一定是最短的,因为两颗树交替生长也就等价于原来的一棵树一层一层生长。此外,交替的顺序也很有讲究,对于当前两颗树的最底层,取节点少的那一个进行生长,这主要是为了避免树生长的太大。由于需要在一棵树最底层查找是否与另一颗树最底层有相同节点,因此这里不使用栈来保存每一层,而是采用set,这样主要是方便节点查找。为了选择节点数更少的那一个底层进行生长,每次生长前,比较两颗树最底层节点数量(使用set.size()),保证s1为节点更少的那一个底层(如果更多则使用swap交换),方便处理。而且每次生长完后要把s1给替换成新生长的那一层cur。
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
// 单向BFS
unordered_set<string> wordSet(wordList.begin(), wordList.end());
if (wordSet.find(endWord) == wordSet.end()) return 0;
queue<string> que;
que.emplace(beginWord);
wordSet.erase(beginWord);
int path = 0, len = beginWord.size(); char temp;
while (!que.empty()) {
++path;
int n = que.size();
for (int s = 0; s < n; ++s) {
string word = que.front(); que.pop();
for (int i = 0; i < len; ++i) {
temp = word[i];
for (char j = 'a'; j <= 'z'; ++j) {
word[i] = j;
if (word == endWord) return path + 1;
if (wordSet.count(word)) {
que.emplace(word);
wordSet.erase(word);
}
}
word[i] = temp;
}
}
}
return 0;
// 双向BFS
unordered_set<string> s1, s2, wordSet(wordList.begin(), wordList.end());
if (!wordSet.count(endWord)) return 0;
int res = 0, len = beginWord.size();
char temp;
s1.insert(beginWord);
s2.insert(endWord);
wordSet.erase(beginWord);
wordSet.erase(endWord);
while (!s1.empty() && !s2.empty()) {
++res;
if (s1.size() > s2.size()) swap(s1, s2);
unordered_set<string> cur;
for (string word: s1) {
for (int i = 0; i < len; ++i) {
temp = word[i];
for (char c = 'a'; c <= 'z'; ++c) {
word[i] = c;
if (s2.count(word)) return res + 1;
if (!wordSet.count(word)) continue;
cur.insert(word);
// 从单词表里删去来代替额外的visited
wordSet.erase(word);
}
word[i] = temp;
}
}
s1 = cur;
}
return 0;
}
};
841. 钥匙和房间
Note: DFS和BFS均可,但DFS可能更加适合。这里要明确一点,如果是找最短路径,一定要BFS,并且如果确定起点终点,那么可以双向BFS。若使用DFS,要注意是遍历整树,还是找到一条路径,前者返回值应为void,后者最好为bool,一旦找到目标路径就返回,如本题中,只要遍历的房间数等于房间总数就可以返回。
另外,像本题这样的DFS不需要回溯,主要是因为求的是可到达性,判断0是否可以到达所有其他节点,而不是求全部可行路径(如果是求一条可行路径,也不需要回溯)。另外还有之前的岛屿问题,也就是染色问题中的DFS也不需要回溯,主要就是因为它们只关注可到达性,即一个节点只要到达过,我就没必要再次到达。
463. 岛屿的周长
Note: 这题直接算就行了,还不如不用搜索。
重要※:并查集代码模版:
int n = 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
// 并查集里寻根的过程
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}
// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 将v->u 这条边加入并查集
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
1971. 寻找图中是否存在路径
Note: 哇,并查集真的好快!(喜)。这道题如果用搜索会慢死,因为数据量太大,而且并查集要注意路径压缩。另外有一点,路径存在性问题确实很适合并查集,但是,有向图不可以使用并查集(除非有强连通分量,等效于无向图)!原因是并查集是用来检测连通分量的,有向图中可能存在节点单向连接的情况,即使两个节点根节点相同(属于一个连通分量),也不一定一个能达到另一个,如下图:
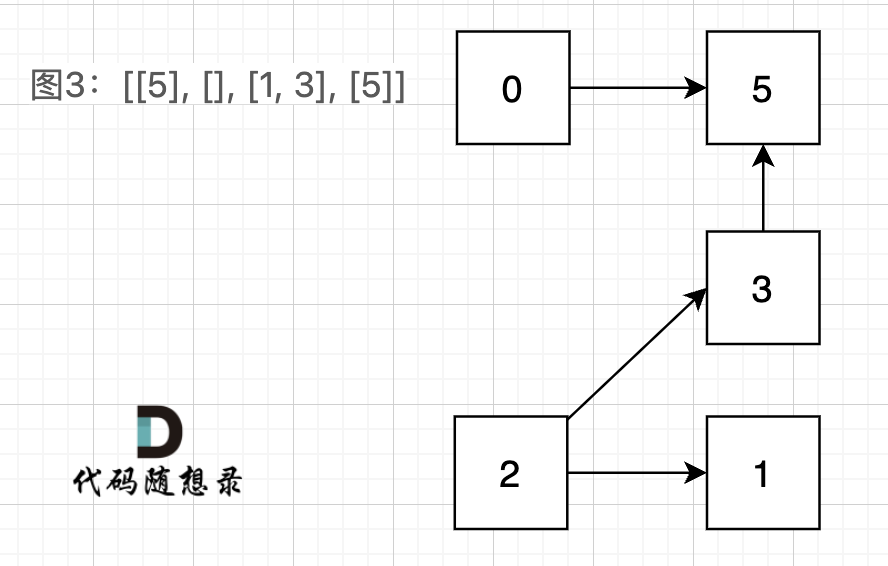
685. 冗余连接 II
Note: 本题要考虑的因素较多,对于这条冗余的边,其要么使得某一个节点入度为2,要么形成了一个有向环。为处理第一种情况,我们遍历边数组来统计入度,并同时记录节点的入边对应的索引(边数组中的索引,这个记录需要n*2大小的二维数组connect,因为每个节点最多两条入边)。一旦在此过程中发现节点入度为2,那么从记录数组中取出该节点第二条入边,然后检查删除该边是否会形成树(使用并查集,在使用边数组建立并查集时忽略该边,然后检查建立过程中是否发生成环,如果是,那么删除该边并不会形成树,否则相反),如果删除该边会形成树,那么删除的就是这条边(第二条入边),否则删除的应为第一条入边;
否则,冗余边一定形成了一个有向环,由于需要去掉边数组中位置最后的冗余边,那么这条冗余边一定是使得成环发生的那一条边(因为环上任一条边其实都可以删,而真正成环的那一条边一定是最后才加进来的),使用并查集判断即可。
class Solution {
public:
int* parent;
int find(int u) {
return parent[u] == u ? u : parent[u] = find(parent[u]);
}
void join(int u, int v) {
parent[find(v)] = find(u);
}
void init(int n) {
for (int i = 0; i <= n; ++i) parent[i] = i;
}
// 看看删去edgeIdx对应的边后是否能形成树
bool IsExtraEdge(const vector<vector<int>>& edges, int edgeIdx) {
int n = edges.size();
init(n);
for (int i = 0; i < n; ++i) {
if (edgeIdx == i) continue;
// 删去该边,仍无法形成树,则返回false
if (find(edges[i][0]) == find(edges[i][1])) return false;
join(edges[i][0], edges[i][1]);
}
return true;
}
// 获取形成有向环的边
int getCyclicEdge(const vector<vector<int>>& edges) {
int n = edges.size();
init(n);
for (int i = 0; i < n; ++i) {
if (find(edges[i][0]) == find(edges[i][1])) return i;
join(edges[i][0], edges[i][1]);
}
return 0;
}
vector<int> findRedundantDirectedConnection(vector<vector<int>>& edges) {
int n = edges.size();
parent = new int[n + 1];
int* inDegree = new int[n + 1];
memset(inDegree, 0, sizeof(int) * (n + 1));
int** connect = new int* [n + 1];
for (int i = 0; i <= n; ++i) {
connect[i] = new int[2];
memset(connect[i], 0, 2 * sizeof(int));
}
for (int i = 0; i < n; ++i) {
int end = edges[i][1];
int connectIdx = ++inDegree[end];
connect[end][connectIdx - 1] = i;
if (connectIdx == 2) {
if (IsExtraEdge(edges, connect[end][1])) return edges[connect[end][1]];
return edges[connect[end][0]];
}
}
return edges[getCyclicEdge(edges)];
}
};