
941. 有效的山脉数组
Note: 山峰问题使用双指针向中间逼近很快。不用考虑怎么返回false,只要true条件满足才返回true,否则返回false
1207. 独一无二的出现次数
Note: 对各个数的出现频率用一个额外的哈希数组记录。
189. 轮转数组
Note: 类似字符串轮转,整体反转后分段反转即可。
922. 按奇偶排序数组 II
Note: 原地交换思想是遍历偶数索引,如果有偶数索引指向奇数,那么说明有另一个偶数放在了奇数索引,因此找到该偶数,和当前奇数交换,这样做尽量避免了不必要的交换(即只交换放错的元素)。
234. 回文链表
Note: 快慢指针,反转右侧链表(以slow开头的链表,由于要切割右侧链表,需要记录slow左侧的一个位置),然后从两端向中间比较。
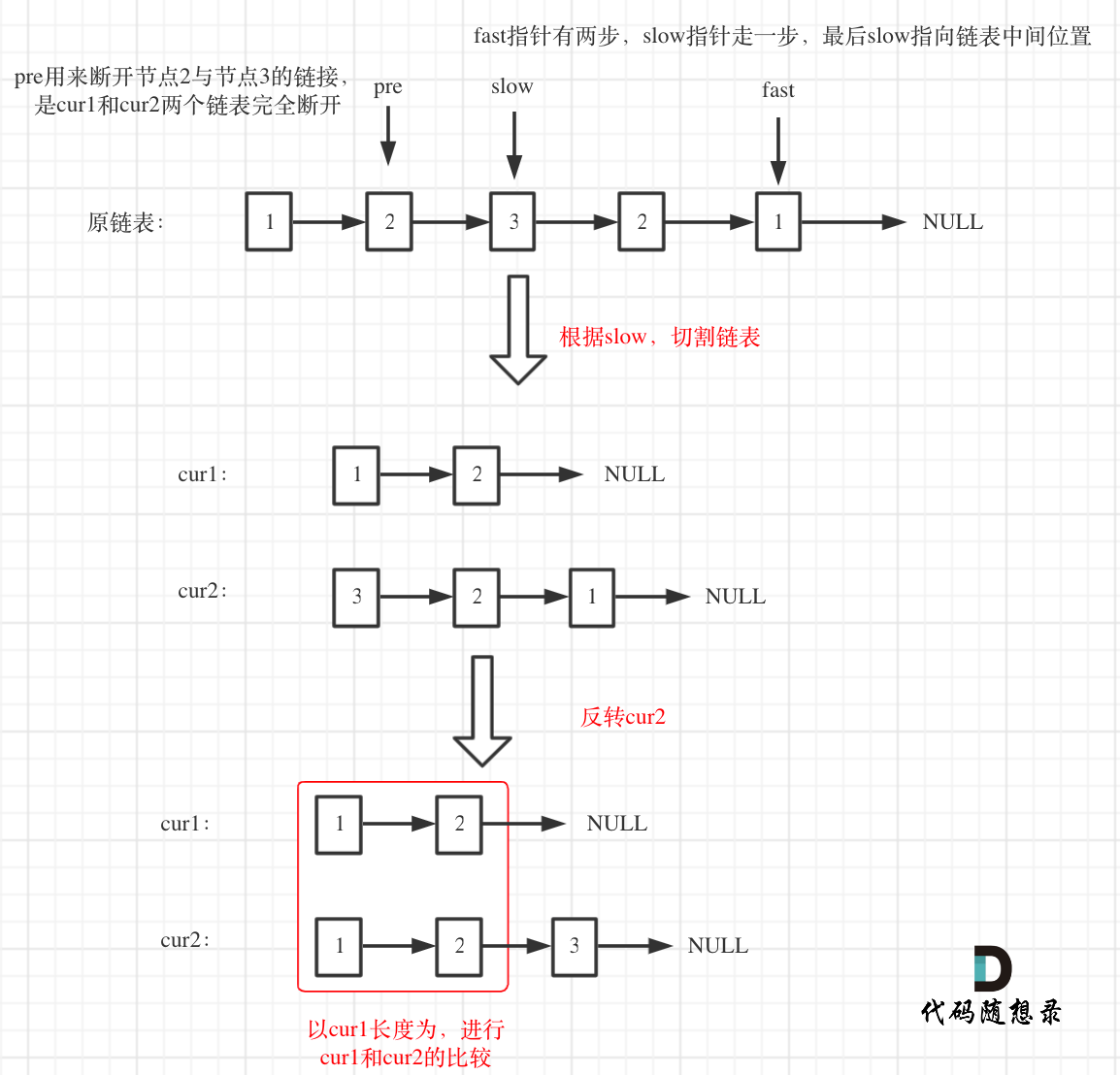
143. 重排链表
Note: 本题细节操作比较难,主要思路是通过快慢指针将链表分为两部分(注意使得左边长度不小于右边),然后反转右边,之后合并两部分即可。
class Solution {
public:
void reorderList(ListNode* head) {
ListNode* fast = head, * slow = head;
// 快慢指针找到索引len/2处,为slow (len为5,slow为2)
while (fast && fast->next && fast->next->next) {
slow = slow->next;
fast = fast->next->next;
}
// 从slow->next开始反转链表,使链表分为两部分
// 使得左边长度一定大于右边(比如上面的长度5,左边长度为3)
ListNode* cur = slow->next, * next, * pre = nullptr;
while (cur) {
next = cur->next;
cur->next = pre;
pre = cur; cur = next;
}
// 断开两部分,第一部分[head, slow], 第二部分[slow->next, pre]
slow->next = nullptr;
// 合并左边(赋给slow)和右边(赋给fast)
slow = head->next; fast = pre;
int count = 0;
while (slow && fast) {
// 偶数则从第二部分中取,否则从第一部分中取
if (count % 2 == 0) {
head->next = fast;
fast = fast->next;
} else {
head->next = slow;
slow = slow->next;
}
head = head->next;
++count;
}
head->next = slow ? slow : fast;
}
};
面试题 02.07. 链表相交
Note: 两种方法,双指针,还有一种就是直接通过把更长的链表起点和更短的对齐,然后同时遍历直到相遇。
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// 双指针
if (!headA || !headB) return NULL;
ListNode* curA = headA, * curB = headB;
while (curA != curB) {
curA = !curA ? headB : curA->next;
curB = !curB ? headA : curB->next;
}
return curA;
// 直接遍历
ListNode* curA = headA, * curB = headB;
int lenA = 0, lenB = 0;
while (curA) {
++lenA; curA = curA->next;
}
while (curB) {
++lenB; curB = curB->next;
}
if (lenA < lenB) {
swap(headA, headB);
swap(lenA, lenB);
}
int diff = lenA - lenB;
while (diff--) headA = headA->next;
while (headA) {
if (headA == headB) return headA;
headA = headA->next;
headB = headB->next;
}
return NULL;
}
};
205. 同构字符串
Note: 注意要双向映射(因为字符只能一对一)
1002. 查找共用字符
Note: 注意需要先单独统计每个单词里的字符频率,然后和总的频率去取最小值,所以需要两个哈希数组记录字符频率(一个是每个单词的,一个是总的),最后根据每个字符最小频率来得到实际的共有字符。
925. 长按键入
Note: 纯纯的面向测试用例编程题。直接贴代码:
class Solution {
public:
bool isLongPressedName(string name, string typed) {
int slow = 0, fast = 0, n = name.size(), m = typed.size();
while (fast < m && slow < n) {
// 等于则各自往前一步,不能用while让typed一直前进
// 主要是防止"maab"和"maaab"这样的被判错
if (typed[fast] == name[slow]) {
++fast; ++slow;
} else {
// 不等于,说明可能是typed长按了(是前一个字符的延续)
// 因此typed前进到与前一字符不同的不同的字符
// 但是如果此时typed在第一个位置,显然是错的
if (fast == 0) return false;
while (fast < m && typed[fast] == typed[fast - 1]) ++fast;
if (fast < m && typed[fast] != name[slow]) return false;
}
}
// 如果名字没匹配完,错误
if (slow < n) return false;
// 如果typed没匹配完,此时只有“typed最后全是长按键入”一种情况是对的
// 比如"alex"和"alexxa"就是错的,而"alex"和“alexxx”是对的
while (fast < m && typed[fast] == typed[fast - 1]) ++fast;
return fast == m;
}
};
844. 比较含退格的字符串
Note: 注意最后一定要(倒序)遍历完两个字符串,不能一个遍历完就返回true。
1382. 将二叉搜索树变平衡
Note: 相比于获取节点值然后重新构造树,更好的办法是直接重用原来的节点,但要注意,节点取出时需要从原树中断开(左右孩子置空),时机为该节点的中序遍历结束时。
52. N 皇后 II
Note: 可以直接使用经典的N皇后算法,但由于这里不需要求出所有实际棋盘,因此可采用状态压缩,用三个int数,分别代表当前放了皇后的列,记为columns;当前棋子左上对角线已占用的列,记为diagonals1;右上对角线已占用的列,记为diagonals2,其中从右到左分别代表0-n - 1列是否被占用。
考虑左上角,对之前放置的任一棋子(row, col),设当前皇后放在(x, y),那么很明显x - row ≠ y - col,即y ≠ x - row + col,那么向下递归一行时,x增加1,那么不能选择的列号相应也要加1,对于下一行皇后可选列号y',有y' ≠ x + 1 - x + y = y + 1,因此统一一下,下一行的diagonals1为当前(diagonals1 | y) << 1 (这里左移一位相当于把列号+1)。考虑右边界,x - row ≠ xol - y,即y ≠ row + col - x,那么相应的下一行的diagonals2为当前(diagonals2 | y) >> 1(列号减一)。column则直接将第y列置1即可。获取每一层的这三个数,对他们进行或运算,即得到当前所有不能放置的位置(标记为1),然后取反,则得到当前所有可放置的位置,相比for剪枝快了很多。
另外这里还需要注意的是,A & (-A)算出的是A的最右边的1的位置,举例:1001 & 0111 = 0001,1110 & 0010 = 0010。因此可以通过这一方法去获取从右开始第一个可放置位置,然后把他置0(可以直接从可放置位置中减掉)。
class Solution {
public:
int backtrace(int n, int row, int columns, int diadonals1, int diagonals2) {
if (row == n) return 1;
int availablePositions = ((1 << n) - 1) & (~(columns | diadonals1 | diagonals2));
int column, count = 0;
while (availablePositions) {
column = availablePositions & (-availablePositions);
availablePositions -= column;
count += backtrace(n, row + 1, columns | column, (diadonals1 | column) << 1, (diagonals2 | column) >> 1);
}
return count;
}
int totalNQueens(int n) {
return backtrace(n, 0, 0, 0, 0);
}
};
649. Dota2 参议院
Note: 贪心模拟,由于可以多轮,for循环外面要套一层while来模拟多轮投票。被ban的议员直接置0,遇到0则忽略,设两个标志位代表两阵营是否还有幸存者,在每一轮投票过程中,若某阵营有人能投票,则该阵营有幸存者,每轮开始前先假设均无幸存者,每轮结束后检查是否两阵营都还有幸存者,若是则继续下一轮,否则有幸存者一方获胜。
5. 最长回文子串
Note: 这题最好不要用动态规划,会有大量无用计算,采用中心扩散更好,可以大量剪枝。
132. 分割回文串 II
Note: 这题由于求数量,不需要用回溯。可以用动态规划,设dp[i]为s[0:i]的最小分割次数,那么对于任意j < i,如果s[j+1:i]是回文串,那么dp[i] = min(dp[i], dp[j] + 1),遍历所有这样的j来确定最终的i,由于s[0:i]长为i+1,因此dp[i]的初值应该为其分割最大次数,也就是i(最少每段一个字符,最多可以分i次)。可以用动态规划和中心扩散两种方法,在动态规划同时可以确定dp数组,中心扩散时则不能。
class Solution {
public:
int minCut(string s) {
int n = s.size();
vector<vector<bool>> isPalindrome(n, vector<bool>(n, false));
vector<int> dp(n);
// 中心扩散
function<void(int, int)> centerDiffuse = [&](int l, int r) {
while (l >= 0 && r < n) {
if (s[l] != s[r]) break;
isPalindrome[l][r] = true;
--l; ++r;
}
};
for (int i = 0; i < n; ++i) {
centerDiffuse(i, i);
centerDiffuse(i, i + 1);
}
for (int i = 0; i < n; ++i) {
// 如果[0,i]是回文串,分割次数直接为0
if (isPalindrome[0][i]) {
dp[i] = 0;
continue;
}
dp[i] = i;
for (int j = 0; j < i; ++j) {
if (isPalindrome[j + 1][i])
dp[i] = min(dp[i], dp[j] + 1);
}
}
return dp[n - 1];
// 动态规划
// for (int i = n - 1; i >= 0; --i){
// dp[i] = n - i - 1;
// for (int j = i; j < n; ++j) {
// if (s[i] == s[j] && (j - i < 2 || isPalindrome[i + 1][j - 1])) {
// isPalindrome[i][j] = true;
// if (j == n - 1) dp[i] = 0;
// else dp[i] = min(dp[i], dp[j + 1] + 1);
// }
// }
// }
// return dp[0];
}
};
673. 最长递增子序列的个数
Note: 本题和 300. 最长递增子序列 思想基本一致。都有两种方法:动态规划和贪心二分。对于本题动态规划,除了用dp[i]表示以i结尾的最长递增子序列长度外,额外用一个count[i]来表示以i结尾的最长递增子序列个数,count的更新根据dp来做,比较dp[j] + 1 (j < i且nums[j] < nums[i])和dp[i]的大小,秉持更大则清零,相等则累加的原则,如果dp[j] + 1 < dp[i],那么以j结尾的递增子序列即使加上本数,长度也不可能等于当前的最长递增子序列,因此不考虑它的序列数量;如果是等于,那么以j结尾的递增子序列加上本数,可以达到当前递增子序列最大长度,因此其数量需要累加count[j];如果是大于,那么当前最长递增子序列长度就应该作废了,数量清0,然后重新加上count[j]。记录整个过程中最大的dp[i]作为最长递增子序列长度maxCount,然后到count中去累加长度为maxCount的递增子序列的数量。
class Solution {
public:
int findNumberOfLIS(vector<int>& nums) {
int n = nums.size(), maxCount = 1;
vector<int> dp(n, 1);
vector<int> count(n, 1);
for (int i = 0; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (nums[i] <= nums[j]) continue;
if (dp[j] + 1 < dp[i]) continue;
if (dp[j] + 1 > dp[i]) count[i] = 0;
count[i] += count[j];
dp[i] = dp[j] + 1;
}
maxCount = max(maxCount, dp[i]);
}
int ans = 0;
for (int i = 0; i < n; ++i) {
if (dp[i] == maxCount) ans += count[i];
}
return ans;
}
};
方法二在之前的贪心+二分基础上,加入了前缀和加速计算,直接见代码:
class Solution {
public:
// 二分搜索确定满足f的最小下标
int binarySearch(int n, function<bool(int)> f) {
int l = 0, r = n, mid;
while (l < r) {
mid = l + (r - l) / 2;
if (f(mid)) {
r = mid;
} else {
l = mid + 1;
}
}
return l;
}
int findNumberOfLIS(vector<int>& nums) {
// 贪心+前缀和+二分
// d[i]表示长度为i的递增子序列的末尾数字历史,一定是非递增的
// cnt[i][j]则表示以d[i][j]结尾的长度为i的递增子序列的数量
vector<vector<int>> d, cnt;
for (auto& num: nums) {
// i是当前num该放入的递增子序列末尾数字历史的序列长度,即num应放在d[i]末尾
// 原因是i左侧的序列历史其末尾数字都<num,因此不可以放入num(贪心)
int i = binarySearch(d.size(), [&](int i){return d[i].back() >= num;});
int c = 1;
if (i > 0) {
int k = binarySearch(d[i - 1].size(), [&](int k){return d[i - 1][k] < num;});
// 假设当前n个数,则前缀和数组cnt长度n+1,其中cnt[i]代表实际count[0 - i-1]
// cnt.back()-cnt[k] = cnt[n]-cnt[k]
// = 实际count[0 - n-1] - 实际count[0 - k-1] = 实际count[k - n-1]
// 由于搜索得到的k左边都是≥num的,从k开始直到d[i-1]末尾d[i-1][n-1]都是<num的,
// 那么累加这部分数量就得到当前数num结尾的长度为i的递增子序列数量
c = cnt[i - 1].back() - cnt[i - 1][k];
}
// 所有d[i]的末尾数字都小于num,那么最长递增子序列长度加1
if (i == d.size()) {
d.push_back({num});
cnt.push_back({0, c});
} else {
// 否则放在当前d[i]末尾
d[i].push_back(num);
cnt[i].push_back(cnt[i].back() + c);
}
}
return cnt.back().back();
}
};
841. 钥匙和房间
Note: 为什么这题递归不需要回溯,而 332. 重新安排行程 递归需要回溯呢,个人理解是,本题在深搜时并不改变节点状态,仅仅是记录当前节点已经访问过,而322.重新安排行程是会改变节点状态的,因此需要回溯。这也可以推广到一般结论,如果搜索过程不改变节点状态,那么就不需要回溯(除染色问题,这类问题我们的目的就是改变节点状态);否则如果搜索过程需要改变节点状态,而这并不是我们的最终目的(仅仅是临时状态),那么就需要回溯,否则将导致别的路径无法搜索。
127. 单词接龙
Note: 注意本题双向BFS和单向BFS还有一个重要的区别:
// 这句必须在下一句前面,因为我们的目的是在另一颗树上找到当前这个突变单词
// 那么很明显,如果能找到,它一定在另一颗树上被访问过了,不应该先去判断
// 是否访问过,而应先在另一颗树上找该单词,否则一定是找不到的,
// 因为该单词被忽略了,单向BFS没有这种问题,关键问题在于这里的访问记录
// 同时记录了两颗树是否访问过该单词,而单向BFS只记录一棵树,那么先判断访问
// 还是先判断找到先后顺序是随意的
if (s2.count(word)) return res + 1;
if (!wordSet.count(word)) continue;
31. 下一个排列
Note: 当寻找下一个排列时,我们需要寻找最右侧的一段非递增序列,这段序列左边的第一个数(记为i)是需要被增大的数,因为这相当于其右边的序列已经达到最大值,不可以再增大,比如12543,其右侧的非递增序列543已经是最大值,因此需要增大左一位的2,如何变更呢?考虑到字典序的下一位,增大的幅度应该最小,而且增大后的数字应从右边序列里选择(而不是左边,因为左边是不应该变化的!),那么由于右侧序列是非递增的,那么从后向前遍历这个序列,找到第一个比i大的数,记为j,这个数是右侧序列中最小的可让i增大的数字,因此将它们交换,可以证明交换过后右侧序列的非递增性不变:
假设原来j左侧数字为m,右侧为n,由于非递增,那么有m ≥ j ≥ n,而j是右侧序列中从后向前第一个比i大的数,因此有n ≤ i < j,因此有n ≤ i < j ≤ m,可见i和j的交换不会影响右侧序列的非递增性,因此再将这段序列反转,就得到下一个排列。
1356. 根据数字二进制下 1 的数目排序
Note: 使用A &= (A - 1)来删掉A末尾的0,然后每删一次count就加1,直到A为0,得到的count就是A中1的个数。还可以用编译器提供的的_builtin_popcount黑科技。